Elasticsearch
1、集群部署
1.1、部署说明 生产机器建议配置: 最低 8C / 16 G
三节点: 10.51.8.120 10.51.8.121 10.51.8.122 配置文件:
[root@es001 ~]# cat /usr/local/elasticsearch-8.2.0/config/elasticsearch.yml | grep -v "#"
cluster.name: my-elasticsearch
node.name: es001 #每台机器只需要修改此处
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["10.51.8.120","10.51.8.121","10.51.8.122"]
#master选举最少的节点数,这个一定要设置为N/2+1,其中N是:具有master资格的节点的数量,而不是整个集群节点个数。
cluster.initial_master_nodes: ["10.51.8.120","10.51.8.121","10.51.8.122"]
xpack.security.enabled: false
xpack.security.enrollment.enabled: false
xpack.security.http.ssl:
enabled: true
keystore.path: certs/http.p12
xpack.security.transport.ssl:
enabled: true
verification_mode: certificate
keystore.path: certs/transport.p12
truststore.path: certs/transport.p12
http.host: 0.0.0.0
transport.host: 0.0.0.0
#每台机器需要添加
[root@es001 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
10.51.8.121 es002
10.51.8.122 es003
10.51.8.120 es001
单节点启动集群: 说明: 守护进程方式启动: 进入软件的安装目录,进入到bin 执行:sh elasticsearch -d -p pid
[es@es001 elasticsearch-8.2.0]$ ./bin/elasticsearch
原因: 尚未发现或选择主节点,一次选择至少需要2个ID为的节点

启动之后过一段时间报错:找不到节点
 按照上面方式,首先但节点启动集群,如果其他节点没有启动,首先会有图1的提示,过一段时间会有图2提示连接不到节点。
按照上面方式,首先但节点启动集群,如果其他节点没有启动,首先会有图1的提示,过一段时间会有图2提示连接不到节点。
然后启动第二个节点 然后在节点1看日志,显示已经有一个节点加进来 ,显示主节点已更改,当前是es002
 日志提示:
日志提示:
current.health="GREEN" message="Cluster health status changed from [YELLOW] to [GREEN] (reason: [shards started [[.geoip_databases][0]]])." previous.health="YELLOW" reason="shards started [[.geoip_databases][0]]"
现在的health=“GREEN”message=“群集运行状况从[黄色]更改为[绿色](原因:[碎片已启动[.geoip_数据库][0]])以前的health=“YELLOW”reason=“碎片已启动[.geoip_数据库][0]。”
然后在es003加入第三个节点:
在es001上看到的日志
 在es002上看到的日志
在es002上看到的日志
es002为主节点
 查看集群状态:
查看集群状态:
 https://github.com/didi/LogiEM
https://github.com/didi/LogiEM
分片在创建好,后期不能修改
GET /_cat/indices
1、创建数据库 创建数据库就是在es中创建索引,下面创建索引testdb 向ES服务器发送PUT请求: http://x.x.x.x:9200/testdb
 查看所有的索引:
查看所有的索引:
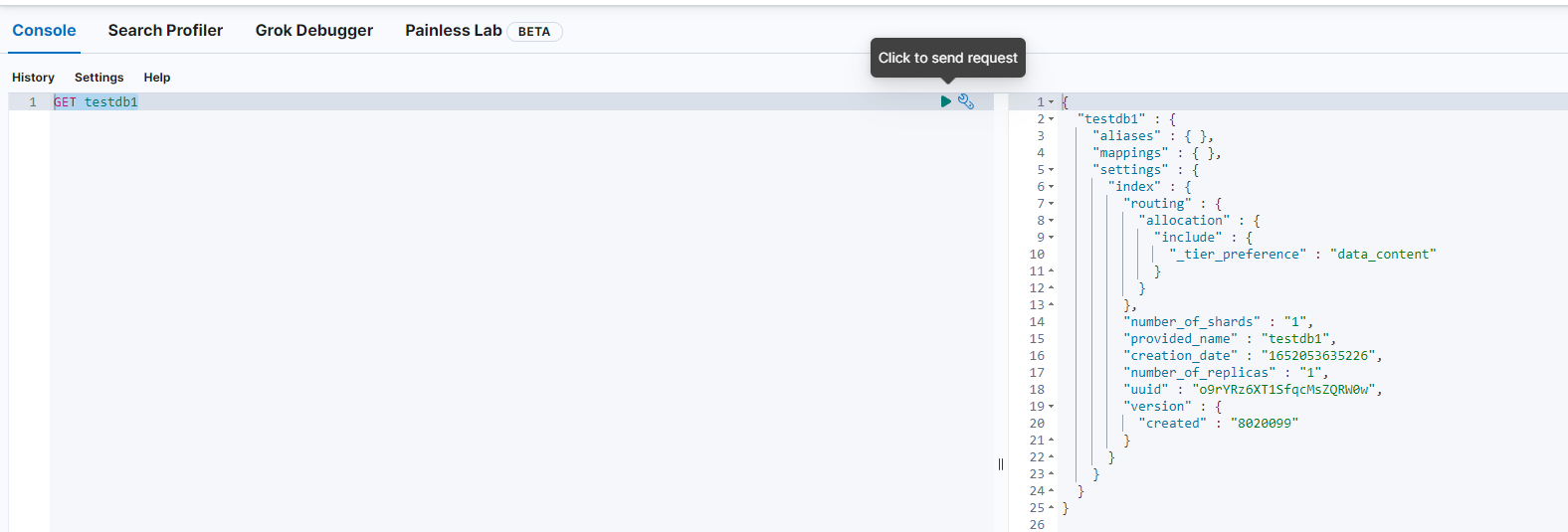 ''
''
删除索引:

2、添加数据 doc 文档 在新版本中没有type概念,就是没有表的概念。

以上_id是自动生成的。也可以自定义,通过下面的方式。

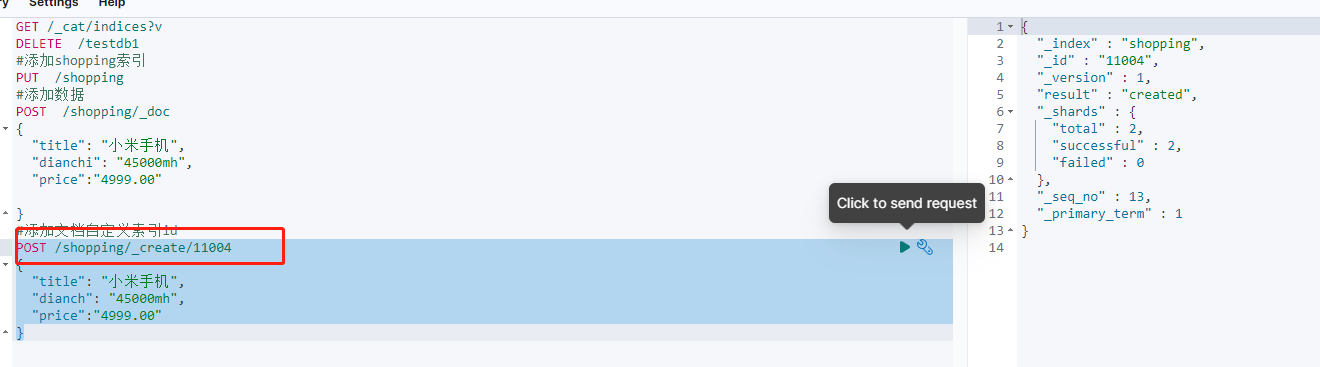 操作记录
操作记录
GET /_cat/indices?v
DELETE /testdb1
#添加shopping索引
PUT /shopping
#添加数据
POST /shopping/_doc
{
"title": "小米手机",
"dianchi": "45000mh",
"price":"4999.00"
}
#添加文档自定义索引id
POST /shopping/_create/11004
{
"title": "小米手机",
"dianch": "45000mh",
"price":"4999.00"
}
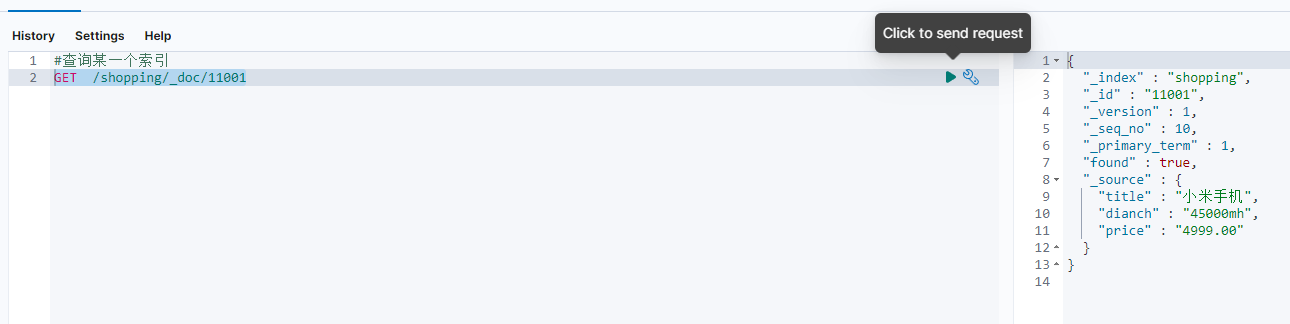
查询一条索引文档
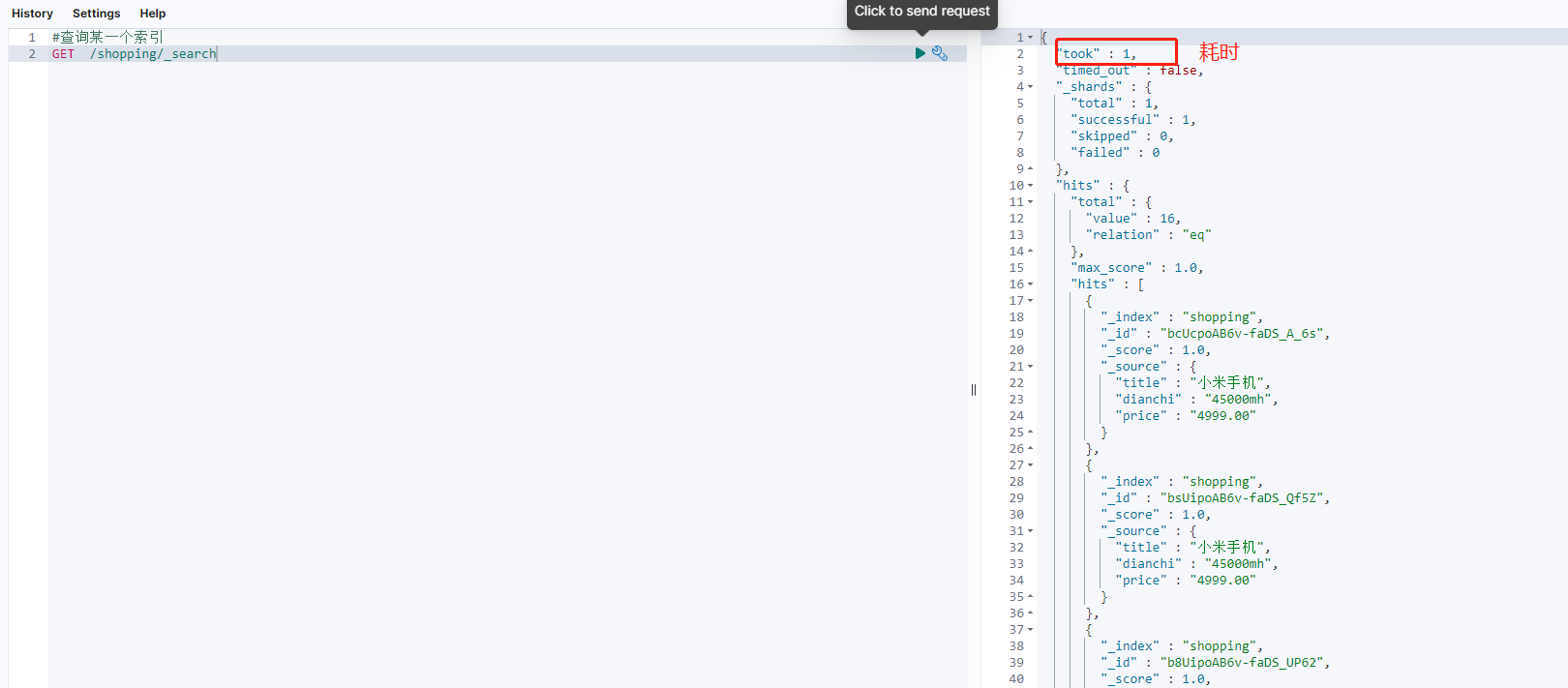
查询所有的索引文档
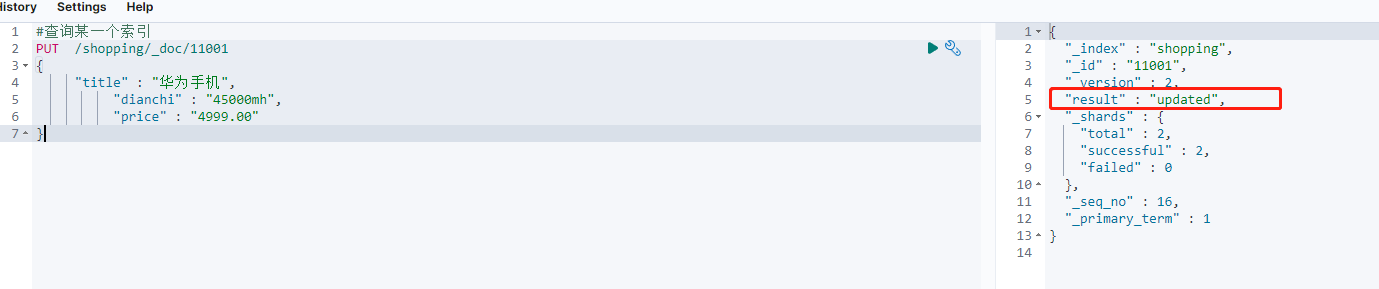
 修改全部数据
修改全部数据
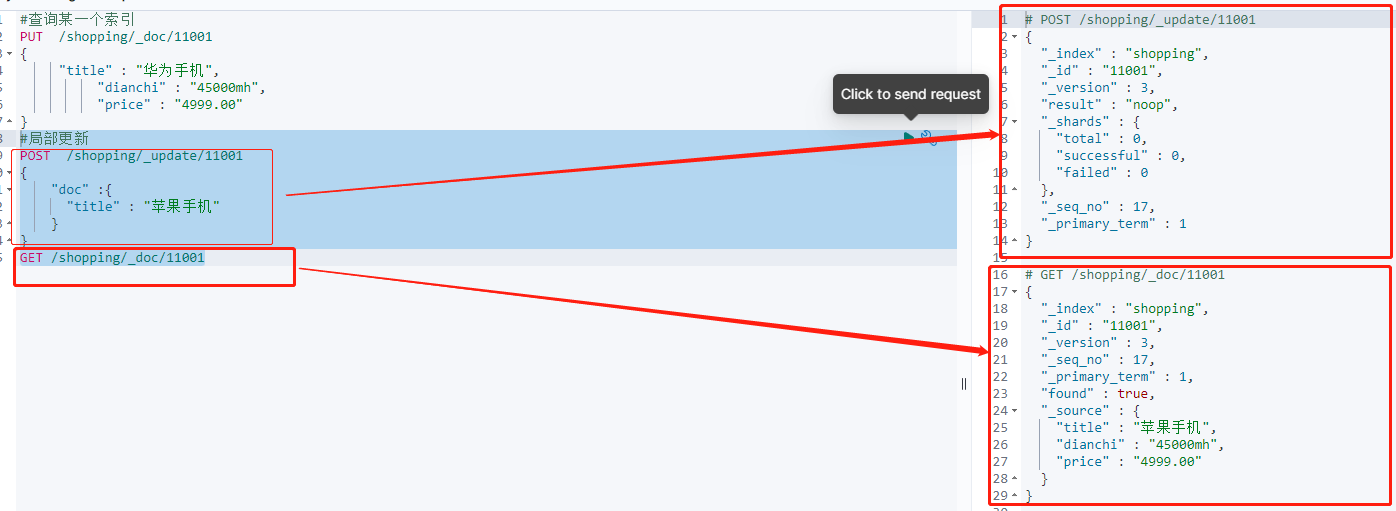
 修改局部数据
修改局部数据
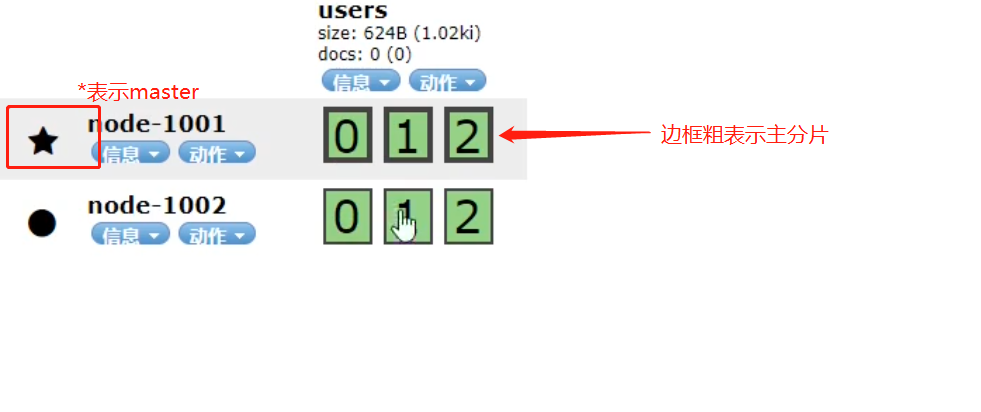
cur /_cat/nodes #查看节点
es默认是一个分片,一个副本。
 一些说明:
一些说明:
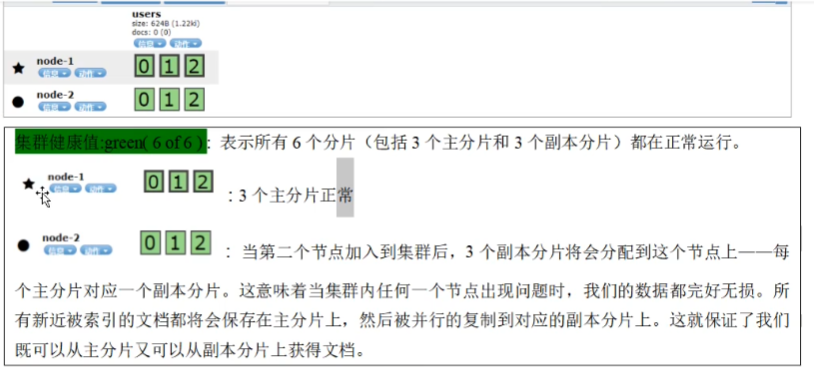 主分片在创建索引的时候已经定下来,后续没法修改,但是修改其副本,也可以提高访问量。
主分片在创建索引的时候已经定下来,后续没法修改,但是修改其副本,也可以提高访问量。
PUT /user/_settings
{
"number_of_replicas": 2
}

当一个节点出现故障时,重启故障节点,一定要在配置文件中discover中添加集群节点信息,否则无法找到集群节点。
2、容器部署
三台机器: 创建目录
sudo mkdir -p /app/server/elasticsearch/temp/config
sudo mkdir -p /app/server/elasticsearch/temp/data
sudo mkdir -p /app/server/elasticsearch/temp/logs
修改权限
sudo chmod 777 /app/server/elasticsearch/temp/config
sudo chmod 777 /app/server/elasticsearch/temp/data
sudo chmod 777 /app/server/elasticsearch/temp/logs
配置文件参考
cluster.name: skywalking_demo
node.name: beijing-k8s-node01 #当前主机名
node.master: true
node.data: true
network.host: 0.0.0.0
http.port: 9200 #外部监听端口
transport.port: 9300 #集群内部通信端口
discovery.seed_hosts: ["10.51.8.112:9300","10.51.8.113:19300","10.51.8.114:9300"] #候选 master
cluster.initial_master_nodes: ["10.51.8.112","10.51.8.113"] #初始化 master
http.cors.enabled: true
http.cors.allow-origin: "*"
磁盘挂载:
/app/server/elasticsearch/temp/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
/app/server/elasticsearch/temp/data:/usr/share/elasticsearch/data
/app/server/elasticsearch/temp/logs:/usr/share/elasticsearch/logs
容器启动:
[root@beijing-k8s-node01 ~]# cat es_compose.yaml
version: '3'
services:
es_node01:
image: registry.cn-hangzhou.aliyuncs.com/zlq_registry/elasticsearch:7.17.3
environment:
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms1024m -Xmx1024m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- /app/server/elasticsearch/temp/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- /app/server/elasticsearch/temp/data:/usr/share/elasticsearch/data
- /app/server/elasticsearch/temp/logs:/usr/share/elasticsearch/logs
network_mode: host
networks:
es-net:
driver: bridge
[root@beijing-k8s-node02 ~]# cat es_compose.yaml
version: '3'
services:
es_node02:
image: registry.cn-hangzhou.aliyuncs.com/zlq_registry/elasticsearch:7.17.3
environment:
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms1024m -Xmx1024m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- /app/server/elasticsearch/temp/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- /app/server/elasticsearch/temp/data:/usr/share/elasticsearch/data
- /app/server/elasticsearch/temp/logs:/usr/share/elasticsearch/logs
network_mode: "host"
[root@beijing-k8s-node02 ~]#
[root@beijing-k8s-node03 ~]# cat es_compose.yaml
version: '3'
services:
es_node03:
image: registry.cn-hangzhou.aliyuncs.com/zlq_registry/elasticsearch:7.17.3
environment:
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms1024m -Xmx1024m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- /app/server/elasticsearch/temp/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- /app/server/elasticsearch/temp/data:/usr/share/elasticsearch/data
- /app/server/elasticsearch/temp/logs:/usr/share/elasticsearch/logs
network_mode: "host"
启动后验证:
curl -l http://192.168.20.20:19200
查看集群状态
curl -X GET "192.168.20.20:19200/_cat/health?v"
查看节点
curl -X GET "192.168.20.20:19200/_cat/nodes?v&pretty"
查看所有索引
curl -XGET "http://192.168.20.20:19200/_cat/indices?v&pretty"
GET /_cat/nodes: 查看所有节点
GET/_cat/health:查看es健康状况
GET /_cat/master:查看主节点
查看ES健康状态
[root@test apps]# curl localhost:9300/_cluster/health?pretty
{
"cluster_name" : "skywalking_elasticsearch",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 2,
"number_of_data_nodes" : 2,
"active_primary_shards" : 156,
"active_shards" : 296,
"relocating_shards" : 0,
"initializing_shards" : 1,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 99.66329966329967
}
查看ES集群的设置
[root@test apps]# curl localhost:9300/_cluster/settings?pretty
{
"persistent" : { },
"transient" : { }
}
其中persistent为永久设置,重启仍然有效;trainsient为临时设置,重启失效
#查看ES在线的节点
[root@test apps]# curl localhost:9300/_cat/nodes?v
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
172.17.113.125 67 99 7 1.34 2.85 2.31 mdi - node-2
172.17.224.119 48 99 6 1.55 3.54 3.08 mdi * node-1
#存在节点缺失的情况可用该命令查看缺失节点为哪些
相关文档
https://zhuanlan.zhihu.com/p/360762412
可视化工具安装
####### kibana 安装
1 创建文件夹
sudo mkdir -p /app/server/elasticsearch/kibana/config
2 配置文件,kibana.yml
sudo vi /app/server/elasticsearch/kibana/config/kibana.yml
server.port: 9901
server.name: kibana
server.host: "0"
elasticsearch.hosts: ["http://192.168.20.20:19200"]
xpack.monitoring.ui.container.elasticsearch.enabled: true
3 启动配置
/app/server/elasticsearch/kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml
######## elasticsearch-hq 安装
docker run -d -p 9900:5000 elastichq/elasticsearch-hq:release-v3.5.12
3、单节点集群部署
这个配置只适用于ES 7.x
步骤
- 拷贝elasticsearch安装包3份,分别命名es-a, es-b,es-c
- 分别修改config文件夹下的elasticsearch.yml文件内容(如下)
- 分别启动a ,b ,c 三个节点
- 打开浏览器输入: http://localhost:9200/_cat/health?v ,如果返回的node.total是3,代表集群搭建成功,也可以使用head进行连接es,如果出现集群信息,则搭建成功。
注意:如果data目录有已经建立好的索引库的话,需要把data目录清空。
修改配置文件ELASTICSEARCH.YML a节点
http.cors.enabled: true
http.cors.allow-origin: "*"
#节点1的配置信息:
#集群名称
cluster.name: elasticsearch
#节点名称
node.name: node-a
#是不是有资格竞选主节点
node.master: true
#是否存储数据
node.data: true
#最大集群节点数
node.max_local_storage_nodes: 3
#网关地址
network.host: 127.0.0.1
#端口
http.port: 9201
#内部节点之间沟通端口
transport.tcp.port: 9301
#es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node-a", "node-b","node-c"]
#数据存储路径
path.data: /home/es/software/es/data
#日志存储路径
path.logs: /home/es/software/es/logs
b节点
http.cors.enabled: true
http.cors.allow-origin: "*"
#节点1的配置信息:
#集群名称
cluster.name: elasticsearch
#节点名称
node.name: node-b
#是不是有资格竞选主节点
node.master: true
#是否存储数据
node.data: true
#最大集群节点数
node.max_local_storage_nodes: 3
#网关地址
network.host: 127.0.0.1
#端口
http.port: 9202
#内部节点之间沟通端口
transport.tcp.port: 9302
#es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node-a", "node-b","node-c"]
#数据存储路径
path.data: /home/es/software/es/data
#日志存储路径
path.logs: /home/es/software/es/logs
c节点
http.cors.enabled: true
http.cors.allow-origin: "*"
#节点1的配置信息:
#集群名称
cluster.name: elasticsearch
#节点名称
node.name: node-c
#是不是有资格竞选主节点
node.master: true
#是否存储数据
node.data: true
#最大集群节点数
node.max_local_storage_nodes: 3
#网关地址
network.host: 127.0.0.1
#端口
http.port: 9203
#内部节点之间沟通端口
transport.tcp.port: 9303
#es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node-a", "node-b","node-c"]
#数据存储路径
path.data: /home/es/software/es/data
#日志存储路径
path.logs: /home/es/software/es/logs
使用HEAD查看集群信息如下,说明搭建成功
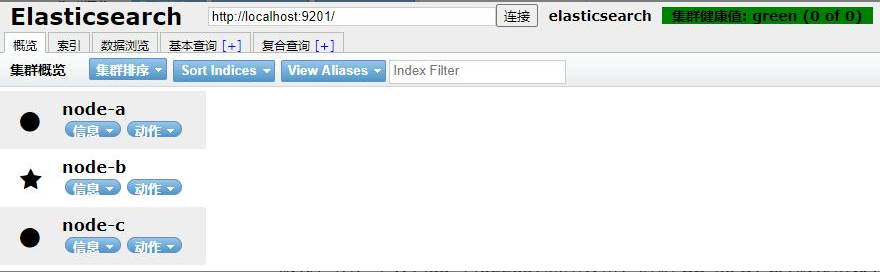
4、head部署
sudo docker run -d \
--name=elasticsearch-head \
--restart=always \
-p 9500:9100 \
registry.cn-hangzhou.aliyuncs.com/zlq_registry/elasticsearch-head:5-alpine
5、es索引导出
elasticdump --input="http://$esAccount:$esPassword@$esIp:$esPort/${index_name}" --output=${back_es_dir}/$index_name.json.bak_$NOW --type=data
6、ES索引日志清理
root@jkyy01:~# cat clean-es-index.sh
#!/bin/bash
# Elasticsearch 相关配置
ES_URL="http://es-cn-7pp2o23h0000e3fk7.public.elasticsearch.aliyuncs.com:9200"
ES_USER="xxxx"
ES_PASS='xxxxxxxxxx'
# 定义需要删除的索引匹配列表
INDEX_EXP_LIST=( [1]=".security_audit_log-2023.05" \
[2]=".security_audit_log-2023.06" \
[3]=".security_audit_log-2023.07" \
[4]=".security_audit_log-2023.08" \
)
# 临时文件路径
TMP_FILE="/tmp/indexlogs-es.txt"
#echo '' > "${TMP_FILE}"
# 清理索引函数
function delindex {
# 获取索引列表
curl -s -XGET -u "${ES_USER}:${ES_PASS}" "${ES_URL}/_cat/indices?v" > "${TMP_FILE}"
for list in "${!INDEX_EXP_LIST[@]}"; do
indexname="${INDEX_EXP_LIST[$list]}"
echo "[INFO] #################开始清理 ${indexname}* 相关索引#####################"
# 提取要删除的索引列表
INDEX_EXP_LIST_ALL=$(grep -n "${indexname}" "${TMP_FILE}" | awk -F ' ' '{print $3}')
if [ -z "${INDEX_EXP_LIST_ALL}" ]; then
echo "[INFO] ${indexname} 相关索引不存在!"
echo -e "\n"
continue
else
echo INDEX_EXP_LIST_ALL: $INDEX_EXP_LIST_ALL
for index in ${INDEX_EXP_LIST_ALL}; do
echo index: $index
if [[ $index =~ ${indexname} ]]; then
echo "[INFO] 开始清理索引 ${index}"
curl -s -XDELETE -u "${ES_USER}:${ES_PASS}" "${ES_URL}/${index}"
echo -e ""
else
echo "[INFO] 跳过 ${index}, 不在范围内"
continue
fi
done
fi
done
}
# 执行清理索引函数
delindex